An Introduction to ML
Tom Read Cutting
What is ML?
ML (MetaLanguage), is a general purpose functional programming language with popular derivatives including F# and OCaml.
Woops!
Wrong Presentation!
An Introduction to Machine Learning and Neural Networks
Tom Read Cutting
Workshop Goals
- Introduce Machine Learning
- Explain the theory behind simple Neural Networks
- Complete a fun neural network challenge
- Introduce a wide array of resources for further learning
Pre-Requisites
You will need:
- Python 3
- A text editor
We will also download these libraries later:
Why Python?
Basically, it is what everyone uses.
It is an incredibly powerful interpreted language with many useful machine learning and visualisation libraries that can interact well with each other.
Furthermore, python is incredibly widely used for other applications, allowing Python+ML to enhance those massively. (eg. Houdini+scikit-learn)
What is Machine Learning?
Machine Learning (ML) is a form of computation where a program is designed to solve specific tasks using models and inference, as opposed to relying on explicit hard-coded instructions.
What types of machine learning are there?
There are three broad categories of machine learning
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Supervised Learning
When a machine learning algorithm attempts to infer a function from labeled training data.
Examples Include
Unsupervised Learning
When a machine learning algorithm attempts to infer some kind underlying structure to unlabelled data.
Examples Include
Reinforcement Learning
When a machine learning algorithm seeks to take actions in order to maximize some kind of reward.
Examples Include
Recap:
We have..
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Neural Networks: An Example
Neural Networks: A Trained Example
The goal of a neural network (in this case!) is to model some function $f(\mathbf{x})$.
Where $\mathbf{x}$ is a multi-dimensional vector, eg. $784$ values representing the pixels of a $28 \cdot 28$ image.
The output could be a number the image represents.
Neural Networks: A Trained Example
So in this example, we want our neural network to take an image of the number $5$ and turn it into the number $5$.
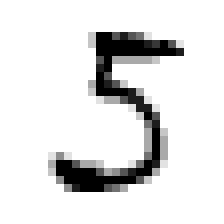 $\rightarrow$ $5$
$\rightarrow$ $5$
Neural Networks: An Explanation
A simple network, the multilayer perceptron:
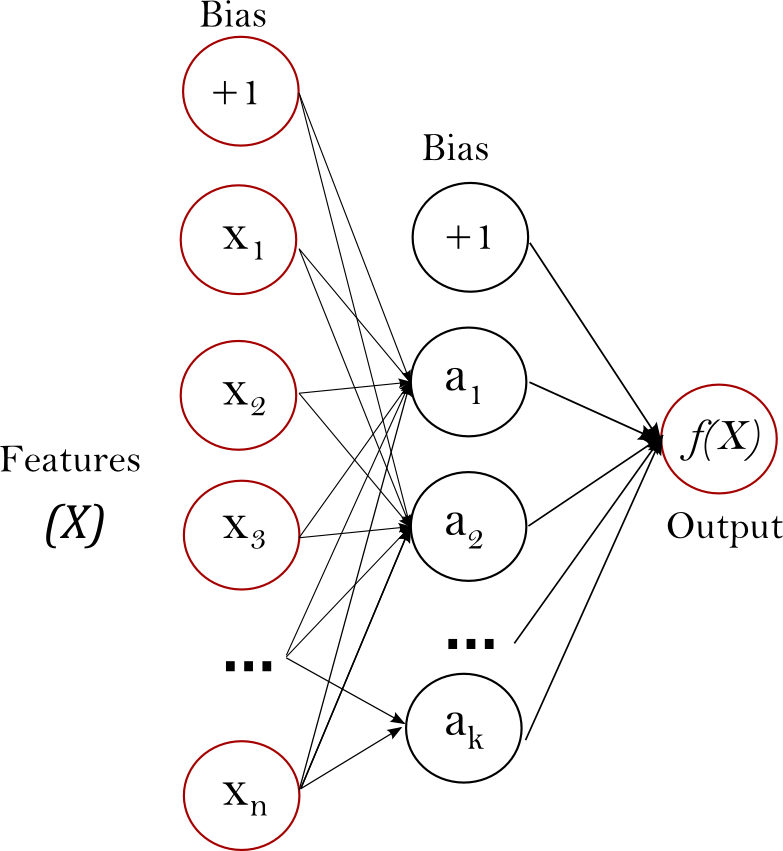
What do we have?
- We have some layers: $1$ input layer, $1$ output layer and $0$+ hidden layers.
- Each layer has a number of neurons.
- The first layer has 784, the last layer has 5.
- Every neuron in each layer is connected to every neuron in the layer before and after.
- Each connection, has some kind of weight.
How does the data flow through the network?
- The input neurons just output the value of the pixel that they correspond to.
- For all other neurons, we have the following equation: $$ a^L_j=\sigma(b^L_j + \sum_{k=1}^{n_{L-1}} w^L_{jk} a^{L-1}_k) $$ We will explore the meaning of this with drawing now...
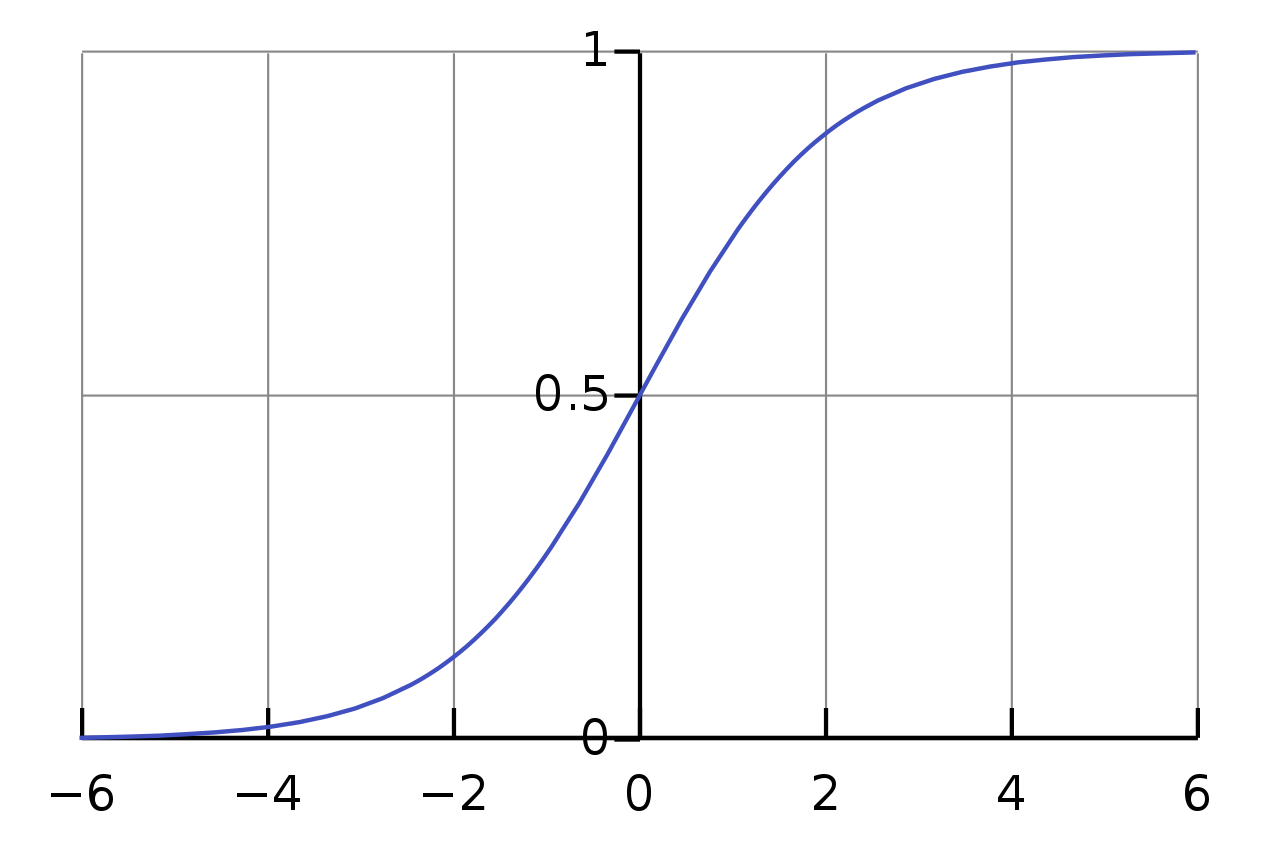
The activation function
$\sigma$ is the activation function, processing all the inputs into a neuron. We will use the sigmoid function:
$$ \sigma (x) = \frac{1}{1 + e^{-x}} $$
The activation function
The output of the sigmoid function looks like this:
Neural Networks: An Explanation
DRAWING TIME!!!! :D
How to train a network: A single-neuron
Some contrived example data
| $x$ | $y$ |
|---|---|
| -2.0 | 4.4 |
| 3.7 | 0.5 |
| 4.7 | -0.3 |
| 1.0 | 1.4 |
| 3.4 | 0.4 |
| 1.9 | 1.4 |
| 0.5 | 2.0 |
| 3.7 | 0.5 |
| -3.7 | 5.6 |
| -1.4 | 3.5 |

Some contrived example data
| $x$ | $y$ |
|---|---|
| -2.0 | 4.4 |
| 3.7 | 0.5 |
| 4.7 | -0.3 |
| 1.0 | 1.4 |
| 3.4 | 0.4 |
| 1.9 | 1.4 |
| 0.5 | 2.0 |
| 3.7 | 0.5 |
| -3.7 | 5.6 |
| -1.4 | 3.5 |

The maths of a single neuron
We can simplify the maths down to (1 layer, 1 neuron, no activation function $\sigma$): $$ a(x)=b + w x $$ This closely matches our desired output function: $$ y = c + m x $$
Finding $b$ and $w$
We need to train the neural network so that it finds $b$ and $w$ to best fit the data.
$$ a(x)=b + w x $$
We can do this with a cost function.
$$ C=\sum_{i=0}^{N-1} (a(x_i) - y_i)^2 $$
Where $(x_i, y_i)$ represents each sample from our training data.
Reducing the cost
Now we have a cost, we can calculate a new weight and bias which minimizes the cost:
$$ w'=w-\mu\frac{\partial C}{\partial w} $$
$$ b'=b-\mu\frac{\partial C}{\partial b} $$
Here, $\mu$ is what we call the learning rate.
Working through the maths...
$$ \frac{\partial C}{\partial w} = \sum_{i=0}^{N-1} 2 x_i ((b + wx_i) - y_i) $$
$$ \frac{\partial C}{\partial b} = \sum_{i=0}^{N-1} 2 ((b + wx_i) - y_i) $$
Example with $\mu=0.01$
$m$ = 0.68, $c$ = 2.75
- $w$ = 1.00, $b$ = 1.00
- $w$ = -1.46, $b$ = 0.95
- $w$ = 0.30, $b$ = 1.50
- $w$ = -1.08, $b$ = 1.52
- $w$ = -0.10, $b$ = 1.86
- $w$ = -0.77, $b$ = 2.16
- $w$ = -0.68, $b$ = 2.66
- $w$ = -0.68, $b$ = 2.73
- $w$ = -0.68, $b$ = 2.75
Example with $\mu=0.001$
$m$ = 0.68, $c$ = 2.75
- $w$ = 1.00, $b$ = 1.00
- $w$ = 0.75, $b$ = 1.00
- $w$ = 0.55, $b$ = 1.00
- $w$ = 0.24, $b$ = 1.01
- $w$ = -0.05, $b$ = 1.06
- $w$ = -0.40, $b$ = 1.28
- $w$ = -0.56, $b$ = 1.97
- $w$ = -0.64, $b$ = 2.50
- $w$ = -0.68, $b$ = 2.74
- $w$ = -0.68, $b$ = 2.75
Example with $\mu=0.1$
$m$ = 0.68, $c$ = 2.75
- $w$ = 1.00, $b$ = 1.00
- $w$ = -23.61, $b$ = 0.54
- $w$ = 373.85, $b$ = 59.07
- $w$ = -6166, $b$ = -937.5
- $w$ = 1.015e+05, $b$ = 1.549e+04
- $w$ = -4.535e+08, $b$ = -6.919e+07
- $w$ = -6.652e+20, $b$ = -1.015e+20
- $w$ = -3.599e+30, $b$ = -5.49e+29
- $w$ = -5.279e+42, $b$ = -8.054e+41
In conclusion
We have worked through the maths of a single-neuron network.
- Representing it with a function $a(x)=b + w x$.
- Applying a cost when applied to training data $C=\sum_{i=0}^{N-1} (a(x_i) - y_i)^2$.
- Calculating cost derivative w.r.t. $w$ and $b$ $\frac{\partial C}{\partial w}$, $\frac{\partial C}{\partial b}$.
- Obtaining $w'=w-\mu\frac{\partial C}{\partial w}$ and $b'=b-\mu\frac{\partial C}{\partial b}$.
- Run the above multiple times to train our network.
- Choose a good $\mu$!
Any Questions?
What glaring flaw do you potentially see with our values for $w$ and $b$?
What about the model overall?
Applying maths to a "full" network
Given $a^L_j=\sigma(b^L_j + \sum_{k=1}^{n_{L-1}} w^L_{jk} a^{L-1}_k)$.
We can use the same cost function and similarly calculate its derivative w.r.t. all weights and biases.
This makes extensive use of the chain rule to backpropagate the cost through the network.
Links at the end the presentation show the full maths behind this.
Before the practical...
Any Questions?
Applying the Principle: the MNIST dataset

Demonstration Time!
- Setup the project folder and install Python dependencies
- Download and load the dataset
- Train and evaluate a neural network on the dataset
Sorting project and dependencies
Create folder and add a text file called "process_digits.py".
Then, ensuring you have Python installed, run:
pip install scikit-learn
pip install numpy
Downloading the dataset
The dataset can be found at http://yann.lecun.com/exdb/mnist/.
However, we will be using MNIST-for-Numpy to download and then load the data into a "process_digits.py".
Training and evaluating a neural network
Your Turn!
By the end of the session, who can come-up with the best accuracy on the testing data?
The next step...
Go back to playground, cover RELU and the like.
Useful Resources
- Neural Networks by 3blue1Brown
- Neural Networks and Deep Learning by Michael Nielsen
- Neural Networks Demystified by Welch Labs
- Machine Learning Course by Andrew Ng at Stanford
- scikit-learn user guide
- Each Other!
Special Thanks
- Huw Bowles and AJ Weeks: For help planning the workshop and providing valuable feedback
- Electric Square: For the support in enabling the workshop
- 3Blue1Brown: For a really helpful video series